Browser-based Access
With a universal, browser-based document retrieval interface, UnForm makes it easy to
browse, search, list, view, administer, and secure archive libraries.
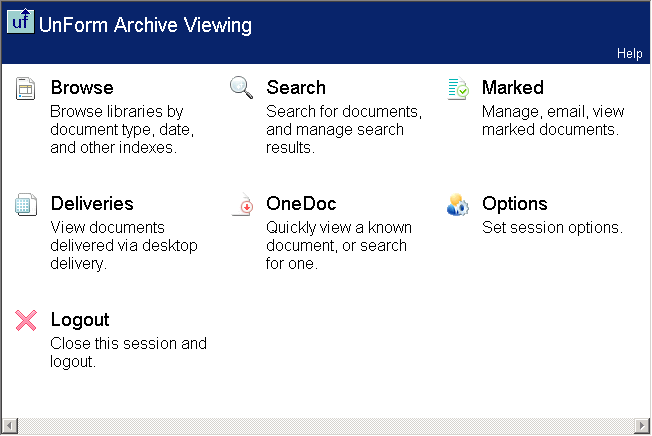
Libraries can scale up to a theoretical capacity of 4-billion documents. Context-sensitive
help links include sample page images, and help guide the user or administrator through the browse,
search and administration functions. Sample archives are included and are referenced in the
help pages. They can aid in the design of a logical custom archiving library and
identification structure suited to the needs of sophisticated end-users.
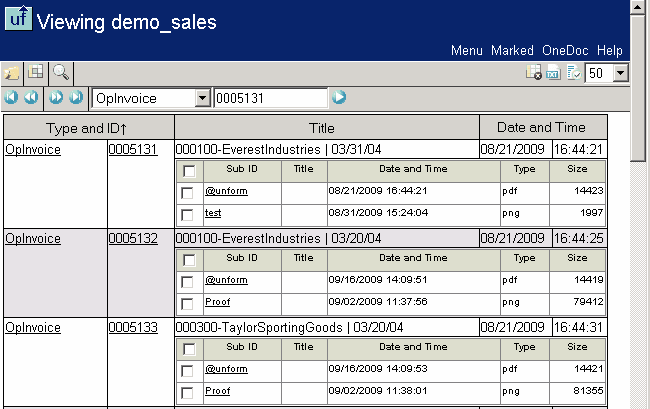
Flexible pre-defined and user-defined document index structures are designed to make
document identification and retrieval practical, fast and easy. Pre-defined index
structures exist for a two-segment type-ID index, and a date-time index. A user-defined
up to ten-segment pipe-delimited category key structure is also provided for indexing.
The browser-based document retrieval interface provides an intuitively sensible drill-down
browse function through the levels of the multi-segmented indexes.
Libraries are file-system-based locations. A three-tiered library-document-image
hierarchy is employed which allows multiple versions of a document, e.g. text and
pdf, to be stored together, uniquely identified by a Sub-ID index, and further allows
multiple text or non-text image or data files to be attached as sub-documents to a
parent. When archiving from an UnForm job, both text and pdf versions are stored
automatically.
Security
Subject to access-rights, document and images being listed and/or viewed in the browser
interface can have properties modified by users to update document status, correct
indexes, and maintain associated notes and keywords at a document level. Files on the
network can be browsed and added as sub-documents from within the browser.
Security is managed by library and by user. All documents are encrypted and compressed
when stored in the library. To access documents, a user login is required, and each
login can be granted read, write, or delete access to a given library, or can be allowed
to access the library based on the library's default access profile.
Search
The browser-based, multi-library search function creates disk-based query-lists of
documents which can be further manipulated independent of other documents in the
library.
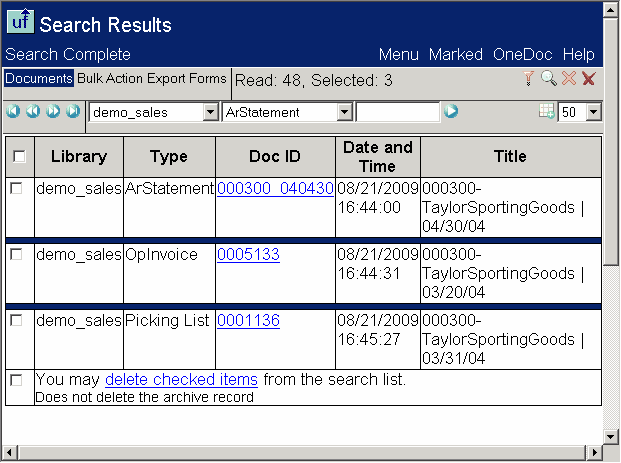 The query lists can be the basis for what are known as bulk actions, which
include copying to new or existing libraries, transferring to new or existing libraries,
and exporting to HTML. The HTML export produces a completely self-contained, browsable,
pure-HTML directory structure suitable for loading on other storage media, such as a
CD/DVD, a zip file, a web site directory, etc.
The query lists can be the basis for what are known as bulk actions, which
include copying to new or existing libraries, transferring to new or existing libraries,
and exporting to HTML. The HTML export produces a completely self-contained, browsable,
pure-HTML directory structure suitable for loading on other storage media, such as a
CD/DVD, a zip file, a web site directory, etc.
Imagine, for example, exporting all of a customer's invoices from a date range to a
zip archive and emailing it to them. Another example would be to off-load old documents
to external storage, then purging them to free up disk space.
|

